Concept Bottleneck Models: Making Neural Networks Speak Human
How interpretable intermediate concepts bridge the gap between black-box predictions and human understanding
Interpretable ML
Deep Learning
Explainable AI
Computer Vision
Author
Rishabh Mondal
Published
March 16, 2026
Interpretable Machine Learning
Concept Bottleneck Models: Making Neural Networks Speak Human
A comprehensive guide to building neural networks that explain their reasoning through human-understandable concepts.
Author
Rishabh Mondal
Published
March 16, 2026
Paper
Koh et al., ICML 2020
Interpretable ML
Deep Learning
Explainable AI
Computer Vision
Part 1: Thinking Lens - Why Interpretability Matters
Before we write any equations or code, let us ask a fundamental question: why do we need interpretable models at all?
Imagine a doctor using an AI system to diagnose skin cancer. The model looks at a dermoscopy image and outputs: “Malignant, 87% confidence.” The doctor asks:
“Why do you think it is malignant?”
The model cannot answer. It is a black box. All the reasoning is hidden inside millions of parameters that no human can understand.
This is much more useful. The doctor can verify each observation. If the model incorrectly detected “irregular borders” on a clearly smooth lesion, the doctor can mentally correct that and reconsider the diagnosis.
This shift from “what” to “why” is the core motivation behind Concept Bottleneck Models.
An intuitive analogy is a student showing their work on a math exam. Even if they get the final answer wrong, the teacher can see where they made a mistake. Without showing work, no feedback is possible.
Black-box model:
input → ??? → prediction
Concept Bottleneck Model:
input → concepts (interpretable) → prediction
↑
Human can inspect and correct here
Pause and Predict
Think of a prediction task in your domain. What intermediate concepts would help a human verify the model’s reasoning?
Medical imaging: anatomical structures, lesion characteristics
Bird identification: wing color, beak shape, size
Loan approval: income stability, debt ratio, employment history
Part 2: The Core Idea - What Are Concept Bottleneck Models?
2.1 Definition
A Concept Bottleneck Model (CBM) is a neural network architecture where predictions must pass through an intermediate layer of human-interpretable concepts.
Instead of learning: \[
f: X \rightarrow Y \quad \text{(input directly to output)}
\]
A CBM learns two functions: \[
g: X \rightarrow C \quad \text{(input to concepts)}
\]\[
f: C \rightarrow Y \quad \text{(concepts to output)}
\]
Where:
\(X\) is the input space (images, text, etc.)
\(C\) is a vector of interpretable concepts (e.g., “has yellow wings”, “is large”)
\(Y\) is the output space (class labels)
The key constraint: all information must flow through \(C\). The model cannot smuggle hidden information past the concepts.
2.2 What makes a concept “good”?
Not all intermediate representations are concepts. Good concepts must be:
Property
Meaning
Example
Meaningful
Expert understands it
“has yellow wings” ✓, “feature_47” ✗
Observable
Can be determined from input
“wing color” ✓, “bird’s mood” ✗
Predictive
Helps determine output
“beak shape” for bird species ✓
The fundamental difference: standard models hide their reasoning, while CBMs make intermediate concepts visible and correctable.
2.3 Code: Setting up our toy dataset
Let us create a simple dataset to understand CBMs concretely. We will simulate bird classification with 4 interpretable concepts.
import torchimport torch.nn as nnimport torch.nn.functional as Fimport numpy as npimport matplotlib.pyplot as plttorch.manual_seed(42)np.random.seed(42)def create_bird_dataset(n_samples=500):""" Toy bird classification dataset. Concepts (4 binary attributes): c0: has_yellow_wings c1: has_long_beak c2: is_large c3: has_forked_tail Species (3 classes): 0: Sparrow - small, short beak, no yellow 1: Warbler - yellow wings, small 2: Hawk - large, long beak, forked tail """ species = np.random.choice([0, 1, 2], n_samples, p=[0.4, 0.35, 0.25]) concepts = np.zeros((n_samples, 4))for i, s inenumerate(species):if s ==0: # Sparrow concepts[i] = [np.random.random() <0.1, # rarely yellow np.random.random() <0.2, # short beak np.random.random() <0.1, # small np.random.random() <0.2] # no forked tailelif s ==1: # Warbler concepts[i] = [np.random.random() <0.9, # usually yellow np.random.random() <0.3, # short beak np.random.random() <0.2, # small np.random.random() <0.3] # sometimes forkedelse: # Hawk concepts[i] = [np.random.random() <0.15, # rarely yellow np.random.random() <0.85, # long beak np.random.random() <0.9, # large np.random.random() <0.8] # forked tail# Simulate image features from concepts W = np.random.randn(4, 8) X = concepts @ W + np.random.randn(n_samples, 8) *0.5return torch.FloatTensor(X), torch.FloatTensor(concepts), torch.LongTensor(species)# Create datasetX, C, Y = create_bird_dataset(500)concept_names = ['Yellow Wings', 'Long Beak', 'Large Size', 'Forked Tail']species_names = ['Sparrow', 'Warbler', 'Hawk']print(f"Dataset: {len(X)} samples")print(f"Features: {X.shape[1]} dimensions")print(f"Concepts: {C.shape[1]} ({concept_names})")print(f"Classes: {len(species_names)} ({species_names})")
Before building a CBM, let us first see what is wrong with standard neural networks. We will train a black-box model and show that it cannot explain its predictions.
The intermediate layers are not constrained to be interpretable. They encode whatever features help minimize the loss, regardless of human understanding.
The model makes a prediction but cannot tell us why. This is the black-box problem.
Part 4: The CBM Architecture
4.1 Thinking Lens
The key insight of CBMs is architectural: force all information to pass through a bottleneck of interpretable concepts. Think of it like a checkpoint where we can inspect what the model “sees” before it makes its final decision.
How should we train the two components of a CBM? This is not as simple as training a single network. We have three choices, each with different trade-offs:
Independent: Train each part separately
Sequential: Train concept predictor first, then label predictor
Joint: Train everything end-to-end together
Think of it like teaching a student:
Independent: Learn facts first, then learn to apply them (separately)
Sequential: Learn facts, then practice applying them
Joint: Learn both together, adjusting facts based on what helps applications
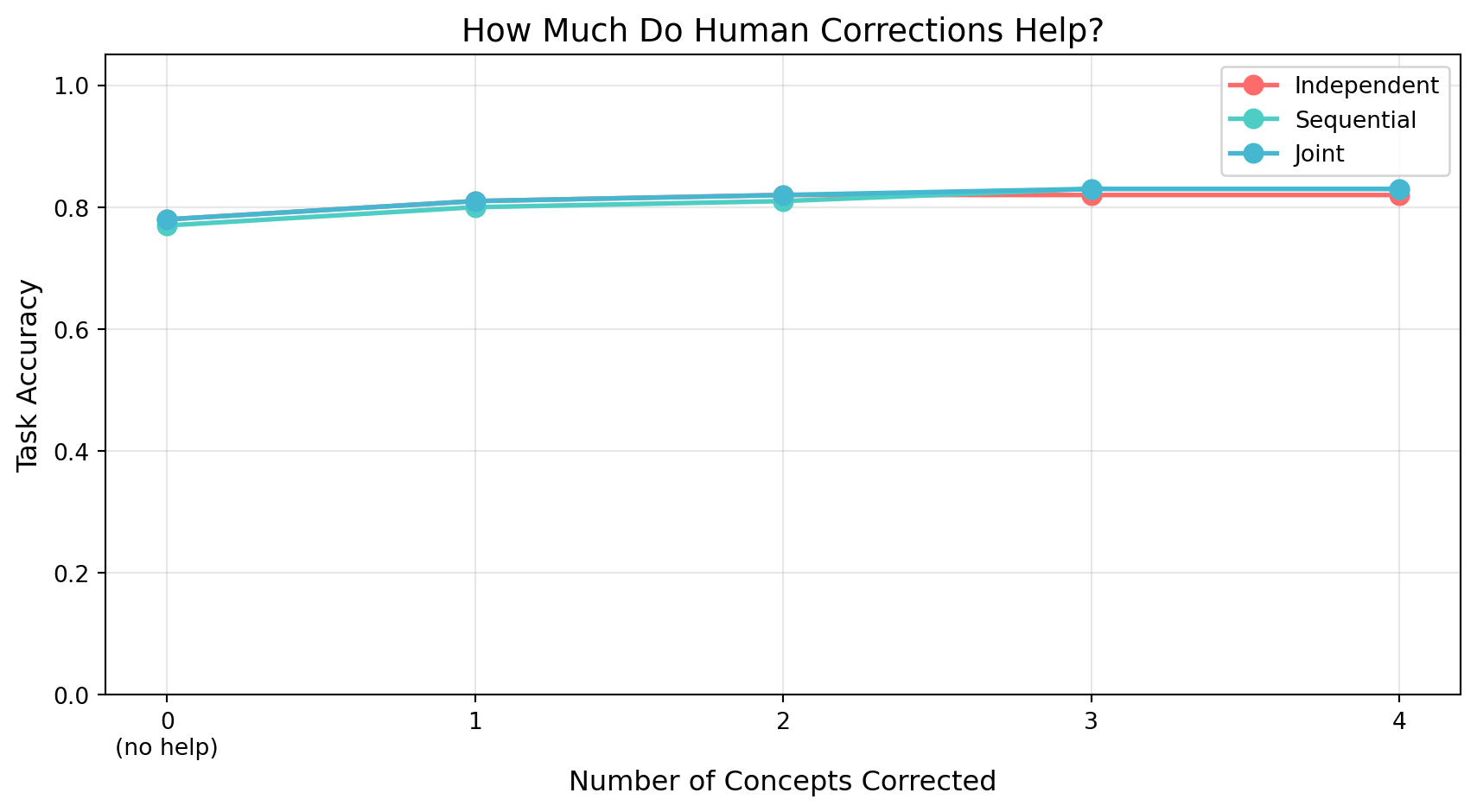
Independent has high concept accuracy but may struggle at test time (label predictor never saw noisy concept predictions)
Sequential handles prediction noise better
Joint typically achieves the best task accuracy by allowing trade-offs
Part 6: The Intervention Mechanism
6.1 Thinking Lens
This is the killer feature of CBMs. Because concepts are interpretable, humans can correct them at test time!
Imagine a doctor reviewing the AI’s concept predictions:
AI predicts: Malignant (75%)
- Asymmetric shape: YES (0.92)
- Irregular borders: YES (0.78) <- Doctor: "No, borders are smooth"
- Multiple colors: YES (0.85)
- Large diameter: NO (0.23)
The doctor corrects “irregular borders” to NO. The model re-computes:
After correction: Benign (68%)
This is human-AI collaboration. The model provides its best guesses, humans fix errors where they have expertise, and the combined system is better than either alone.
6.2 Definition: Intervention
An intervention replaces predicted concepts with ground truth values.
Let \(\hat{c} = g_\theta(x)\) be predicted concepts. Given an intervention set \(\mathcal{I}\) (indices to correct):